In both articles Keith makes a special effort to thank and commend the countless individuals, seen and unseen, who helped run UKNOF over the years and make it what it was.
I am deeply grateful to Keith for acknowledging these contributions.
On my account, I’ve acknowledged, aired and feel able to move on from the feelings of bitter disappointment about what’s come to pass, and instead I’m ever closer to the “smile that it happened” state of mind.
I might continue to grieve for a little while – and in a healthy way – for the UKNOF that was, at the same time I do want to see whatever succeeds it to actually succeed.
To try and make use of the legacy left behind by 20 years (!) of UKNOF and do right by the contributors and community. To take forward the best bits of UKNOF as its foundation.
To enlighten, grow friendships, develop careers, to build networks beyond infrastructure.
So in the coming days I’ll look to the future while at the same time trying to tell some of the UKNOF story, “the best bits”, from my own perspective.
Maybe for my own peace of mind, but also maybe for the success of what’s to come.
After all, there’s 20 years of learning experiences. I was there for a lot of it…
It’s going to take me a while to get my thoughts and words in order on this subject. It is one which is quite emotive for me, for reasons which will become clear. I don’t think I can get this all out, organised in a single post either. So this may be the first of several things I write on the subject.
UKIF has left the building. <thud>
The organisation that ran UKNOF events – UKIF Ltd – has stated they will no longer run the events, and will be winding the company up in 2024.
They state a number of reasons for this, including declining sponsorship in the present macro-economic climate, reduced attendance, and the costs of continuing through Covid. All of these have served to deplete the organisation’s reserves, because while the events did not cover their costs the long term commitments to venues, some made before Covid, had to be kept – UKIF would have had to pay something whether or not the events in 2023 went ahead.
Another reason is the forthcoming retirement of Keith Mitchell, the principal in UKIF Ltd and the founding convener of the UKNOF meetings, without any obvious route for succession.
A not uncommon source of frustration is poor wifi access in public spaces such as hotels, airports, etc., and by extension, poor wifi at events. We’ve all seen the issues – very slow downloads, congestion, dropped connections.
One of the things I do is regularly attend Internet industry events, and by nature of what they are, they are full of geeks, nerds and other types of “heavy user”, and they need their own significant wifi capability to support the event. Yet even those events, which don’t rely on the in-house wifi provision, still run into problems – for instance, the most recent NANOG meeting had some significant wifi issues on the first day, though they did have the challenge of serving over 800 users in a relatively tight space.
I’ve also been involved in setting up connectivity at meetings, so I know from experience that it’s not that difficult to provide good quality wifi. You just need to make a little bit of effort.
This is probably the first of a short series of posts, where I’ll share nuggets of wisdom I’ve picked up along the years. I’m going to assume that if you’re reading this, you know a bit about wifi.
1) Band steering does not work reliably enough
Wi-fi operates on two bands, 5GHz and 2.4GHz. The 2.4GHz spectrum is congested. Most modern clients support both bands. Band steering is an attempt to force clients that can use the 5GHz spectrum off the 2.4GHz spectrum. It works by having a base station “ignore” 2.4GHz association attempts from a client that can associate on 5GHz.
However, experience shows that this is not reliable for all clients, and many clients which could be associated with a 5GHz base station end up associated not only with a 2.4GHz base station, but one which is suboptimal (e.g. further away).
Band steering seems especially problematic when enabled on autonomous base stations. At least on a centrally orchestrated controller-based network, the controller can simultaneously tell all base stations to band steer a particular client.
Which leads me on to…
2) Run separate SSIDs for 5GHz and 2.4GHz bands
If band steering is unreliable, then you need some other way of getting clients on the “right” wifi band. Running separate SSIDs is the best way of doing this.
The majority of modern clients support 5GHz (802.11a). I would therefore recommend that your main/primary SSID is actually 5GHz only. All the clients will ordinarily connect to that.
You can then set up a second SSID which could end in “-2.4” or “-g” or “-legacy” for the non-5GHz clients to connect to. The 2.4GHz clients will only see this SSID and not the 5GHz one. There are significantly fewer 2.4GHz clients around these days.
At the end of the day, both the 5GHz and 2.4GHz wifi SSIDs should then still be bridged to the same backend network so that the network services are the same for the 5GHz and 2.4GHz clients.
3) Turn off 802.11b
Are there any 802.11b only devices still around in regular use?
Disabling 802.11b will restrict your 2.4GHz spectrum to .11g capable devices only, and has the effect of raising the minimum connect speed.
If you know you don’t have to support legacy 802.11b devices, switch off support for it.
4) Restrict the minimum connect speed
The default configuration on some base stations, especially if 802.11b is switched on, is to accept wifi connect speeds as slow as 1Mb/sec.
All you need is one rogue, buggy or distant client to connect at a slow speed and this acts as a “lowest common denominator” to bring your wifi to it’s knees, slowing all clients on that base station to a crawl.
Right. That’s it for today.
Eventually I’ll be showing you how you can run wifi for a 200-300 person meeting out of a suitcase.
I’ve recently returned from the NANOG 61 meeting in Seattle (well, Bellevue, just across the lake), a fantastic meeting with well over 800 attendees. It was good to meet some new folk as well as catch up with some industry contacts and old friends.
One of the topics which came up for discussion was the activities of the Open-IX association. This is a group which exists to promote fairness and open competition between Internet Exchange and Co-location operators in the US, and thus improve the competitiveness of the market for the users of those services, such as ISPs and content providers.
It was originally set-up to address what was something of a market failure and a desire by a number of US network operators to encourage organisations that run Exchange facilities (such as Equinix) to have more transparent dealings with their customer base, such as fair pricing and basic expectations of service level. This is something that is more common in Europe, where a large majority of Internet Exchanges are run as non-profits, owned and steered by their participant communities.
To do this, the Open-IX Association don’t actually plan to own or operate exchanges, but instead act as a certification body, developing a set of basic standards for exchange companies to work to. It’s somewhat succeeded in it’s initial goals of correcting the market failure. New IXP entrants in the shape of the three large European IXPs have entered the North American market, and co-location operators who were previously less active in the interconnection market have become more engaged.
So, one of the questions asked is what next for Open-IX?
(Indeed, my former boss, LINX CEO John Souter even ventured to suggest it’s “served it’s purpose” and could be wound up.)
There has been questions from some smaller IXPs, they can’t meet all the criteria laid down in the OIX-1 standard (and possibly don’t wish to or have means of doing so). Does this some how make them a “less worthy” second-class IXP, despite the fact that they serve their own communities perfectly well?
In particular, both the Seattle Internet Exchange and Toronto Internet Exchange currently can’t comply with OIX-1, but at the same time it’s not important for them to do so. The difference being these are member-driven exchanges, more along the lines of the European model. Their members don’t require them to provide the services which would allow the organisations to confirm to OIX-1.
I don’t think anyone would venture to suggest that the SIX or TorIX are in some way “second class” though, right? They are both well run, have plenty of participants on the exchange fabric, and respected in the IX community.
This is a key difference between these exchanges and commercial operations such as Equinix: The member-driven IXPs such as SIX and TorIX don’t need an Open-IX to set standards for them. Those local communities set their own standards, and it’s worked for them so far.
And maybe that’s where the opportunity lies for Open-IX: To act like this “conscience” for the more commercial operators, in the same way as the members steer the non-profits?
The venue for UKNOF 29 and ISOC’s ION Belfast meeting to be held in September this year is currently looking like another great place for UKNOF to meet – it’s the Assembly Buildings, right in the middle of the city, easy to get to, and a good choice of hotels (from budget options such as Travelodge through to mid-range Jury’s Inn, and the higher end Europa and boutique Fitzwilliam) all less than 2 minutes’ walk away. There’s also some smashing restaurants and bars for the all important networking we come to do at UKNOF.
Don’t be put off by the theatre seating above – this was for the event occurring the next day – we’re looking at either cabaret or classroom seating for our event, there will be somewhere to put your laptops!
We decided on this venue not just because of it’s central location, but the high specification of the AV and technical support provided in house. The home of the General Assembly of the Presbyterian Church in Ireland, the 109 year old building recently benefitted from a massive refurbishment, including a serious tech upgrade.
It has a Gig of bandwidth to the building. The UKNOF connectivity will use this as the transport to bring in our own Internet Access (over a tunnel) with no NAT and native IPv6, provided as usual by Tom at Portfast.
I recently visited to check this all works as anticipated, and it seems to work just fine. The tunnel to Portfast’s Docklands router came up just fine, and 80-90Mb (this being constrained by the router in use as the tunnel endpoint) was achieved with no issues.
The resident IT guys are super-helpful, and have even offered the use of their existing Aruba wifi platform for distributing the UKNOF wifi network in the building. If this works, it will mean that UKNOF doesn’t have to ship a load of access points out to the venue. Our testing revealed some limitations in the current Aruba setup, such as IPv6 RAs and ND apparently being blocked in the current config. Fixing this is on the list of things to do, as they don’t natively run v6 yet as part of their day to day operation so haven’t been concerned about it (until now).
We also need to investigate operating separate 2.4Ghz and 5Ghz wifi SSIDs, they are currently set up single SSID with bandsteering, so we may want to set up with specific radio heads as 5Ghz only.
This is all stuff to work on and resolve with their tech folks in the next few weeks.
Even if we decide we’d rather run our own access points because of the high client density at our meetings, this should be relatively simple and not require transporting lots of kit. The main hall can be covered by 4-6 access points, and there is plenty of structured cabling.
Audio isn’t a problem. A rather nice Allen & Heath desk is permanently installed, and the standard rig includes plenty of radio handheld and lapel mics, and sidetone/foldback is provided for the presenter. On the day desk will be looked after by a professional sound engineer.
The venue even has it’s own permanently installed video system, comprising four HD pan-tilt-zoom cameras with video switching, that can provide an SDI out. Hopefully the folk over at Bogons who support UKNOF with webcasting can ingest this, and avoid having to bring their own camera.
If the big stage and stained glass window backdrop hasn’t scared you off yet, the Call for Presentations is open, and our regular Programme Committee has been strengthened by the addition of David Farrell from Tibus and Brian Nisbet of HEAnet for this meeting to help us find interesting local content.
The RIPE NCC will be holding their Basic and Advanced hands-on IPv6 training courses in the same venue (just a slightly smaller room!) on the Wednesday, Thursday and Friday of the same week.
We’re really looking forward to September, and welcoming Internet Operations folk from the whole of Ireland (both The North and The Republic), the UK mainland, and elsewhere to Belfast.
(It may even be the easiest UKNOF so far for the folk on the Isle of Man to get to?)
My week started in Manchester, where it was the warm up for what turned out to be the largest UKNOF meeting so far – UKNOF 27. In this case the “warm up” was the IX Manchester meeting, facilitated by LINX (who operate IX Manchester).
This is, I think, the first time that UKNOF and one of the regional interest groups in the UK have teamed up and worked to co-locate their distinct, separate meetings on adjacent days in the same venue. It might have been a bit of an experiment, but I hope everyone agrees it was a successful one and we’re able to co-operate again this way some time in the future.
Talking of the venue… what a venue!
UKNOF attendance has been growing of late, and so to protect ourselves against ending up somewhere that couldn’t cope, we eventually chose Manchester Central Convention Complex.
I remember going to help scout the venues for this meeting earlier this year. We looked at various places, small and large. Remember that last time we were in the North West (back in 2010 thanks to the kindness of Zen Internet) only 65 people attended. Even the most recent non-London UKNOF in January 2013 couldn’t break the 100-barrier (and that was with Tref hosting!).
But, during 2013 we’d also had two bumper meetings at 15Hatfields in London and could see that we are definitely growing as a community, so we had to think big, and so we went with the venue that we felt could cope best with the unpredictability.
Initially, we were somewhat awestruck, maybe even a little bit nervous, when choosing a venue like this. It hosts massive conferences, trade shows and events. It’s a serious venue.
But we needn’t have worried, it turns out we’d made the right decision, and the space happily scaled up from a 60-odd person IX Manchester meeting to the 200+ person UKNOF the following day.
UKNOF 27 turned out to be our biggest meeting so far.
…and not in London!
We had over 250 people register. Around 25 cancelled their attendance in the week leading up to the meeting, and around a further 20 no-showed on the day. We’d ordered catering for 210, a good guess I think!
I’ve honestly not heard a bad comment about UKNOF 27. We had some fantastic, interesting and original content delivered by our speakers from within the community. I can’t thank them enough. Without them, without you, there is no UKNOF.
The audio and visual support seemed to work well, but we also learned a thing or two which will be brought to bear at future meetings. The Internet access was nice and stable: we brought our own wifi infrastructure for the meeting, and used Manchester Central’s great external connectivity to Metronet as a “backhaul”.8 wireless access points were used to provide adequate coverage across the rooms, where most meetings previously got by on two. As usual, fantastic support from Tom at Portfast for the connectivity, and Brandon from Bogons.net for our webcast, along with Will and Kay who do connectivity for large events such as CCC who helped set up the additional access points.
Why was UKNOF 27 so successful?
Er, good question.
It was certainly a very easy venue to get to, regardless of how you wanted to get there. Plenty of parking space, easy access to public transport and an international airport just a short train ride away. Possibly even easier than a London venue?
Did the simple act of holding UKNOF in a serious venue such as Manchester Central raise the profile of the event with those who were sat on the fence?
There’s no doubt that the content itself was attractive, especially if (the lack of) bandwidth use was anything to go by.
The food offering from Manchester Central’s own in-house kitchens I thought to be superb, hope others agreed! All prepared from scratch in-house, even the biscuits for the coffee breaks, a definite cut-above a shipped-in offering. I felt you could taste the difference.
Maybe the co-location with the IX Manchester meeting meant that some folk stuck around for the extra day (and vice-versa)?
There seems to be renewed activity in the Internet engineering arena in the North of England at the moment – partly touched on by Mike Kelly’s participation in a panel at the meeting, discussing the relevance of regional infrastructure and it’s role in balancing the distorted London-centric infrastructure that has long characterised the UK’s Internet development…
Dr Mike Kelly: Individual decisions of companies in this room will determine the shape of the internet over the next 15 years #uknof27
…maybe there really are more Internet geeks in the North than the South these days?
Or if we’re going to have that level of influence, it’s just that our thrice-yearly get-together of Internet geeks is coming of age.
That said, I promise that we’ll stay true to our mission of “distribution of clue” and keep our focus on grass-roots Internet engineering and development.
Thanks to everyone who attended, sponsored, spoke, asked questions, or helped us in any way to make UKNOF 27 the success it was.
For those of you who enjoyed us being in Manchester, the good news is that we’re looking at a potential return there in 2015.
Or, I never thought of myself as a narcissist but…
Thanks to the folks at HEAnet, here’s a link to the video of the talk “It’s peering, Jim…” that I gave at the recent INEX meeting in Dublin, where I discuss topics such as changes in the US peering community thanks to Open-IX and try to untangle what people mean when they say “Regional Peering”.
The talk lasts around 20-25 minutes and I was really pleased to get around 15 minutes of questions at the end of it.
I also provide some fairly pragmatic advice to those seeking to start an IX in Northern Ireland during the questions. 🙂
Last week, I was over in Dublin having been invited to give a talk by my gracious hosts at the Irish Internet Exchange Point, INEX. I asked what sort of thing they might like me to talk about. We agreed that I’d talk about various trends in global peering, mainly because the INEX meeting audience don’t do massive amounts of peering outside of the island of Ireland.
(If you need to understand the difference between the UK, Great Britain, Northern Ireland, the Republic of Eire and the island of Ireland this video will be a massive help. Thanks CGP Grey.)
One of the discussions we had was what is meant when we say “Regional” when talking about Internet Exchange points? In the UK, we generally mean exchanges which are outside of London, such as IX Leeds. When a “Regional IXP” is discussed in Africa, they actually mean a “super-national” IXP which possibly interconnects several countries across a region.
Why do the communities in these areas want IXPs that span national boundaries?
The main reason: latency.
There is a lot of suboptimal routing. Traffic being exchanged between adjacent countries on the same continent can end up making a long “trombone-shaped” trip to Europe and back. This has a negative effect on the user experience and on the local internet economy.
Round-trip times from RIPE Atlas probes in Southern African countries to a destination in South Africa
As you can see above, traffic from the test probes Kenya and Angola, along with the Maldives and the Seychelles is likely being routed to Europe for interconnection, rather than being handled more locally, if the round-trip time is an indication of route taken. The probes in Botswana, Zambia and Tanzania do somewhat better, and are definitely staying on the same continent. The African example is one of the obvious ones. Let’s look at something a bit closer to home…
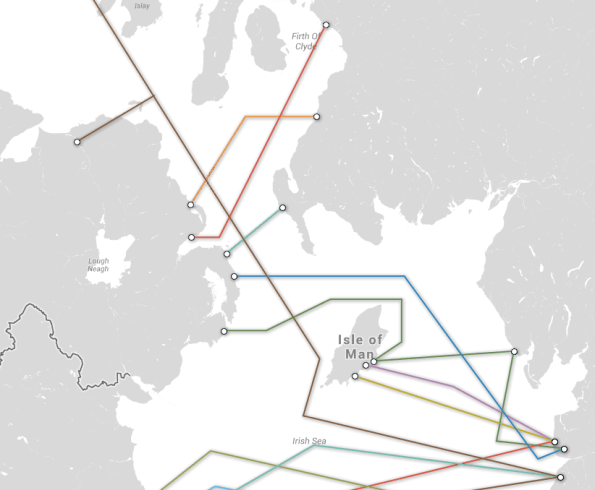
Regional peering in Northern Ireland and Northern Ireland to the Republic of Ireland
There is already a well established exchange point in Dublin, INEX, with a good number of national and international members. Discussions are taking place between Internet companies in Northern Ireland (which, remember, is part of the UK) about their need for a more local place to exchange traffic, likely in Belfast. The current belief is a large amount of the traffic between sources and sinks in Northern Ireland goes to London or Amsterdam.
Firstly, how does traffic get from the UK (and by inference, most of the rest of Europe) and Northern Ireland? This is what Telegeography say:
Submarine Cables UK to NI
RIPE Atlas Probes in Northern Ireland
So, I thought I’d do some RIPE Atlas measurements.
This isn’t meant to be an exhaustive analysis. More just exploring some existing theories and perceptions.
The first trick is to identify probes in Northern Ireland. From the RIPE PoV, these are all indicated as part of the UK (go and watch the video again if you didn’t get it the first time), so I can’t select them by country.
Fortunately, probe owners have to set their probe’s location – there is a certain amount of trust placed in them, there’s nothing stopping me saying my probe is somewhere else, but most probe owners are responsible techy types. The RIPE Atlas people also put the probe locations onto a coverage map.
I also needed some targets. Probes can’t ping each other (well, they can, if you know their IP address, and they’re not behind some NAT or firewall). The Atlas project provides a number of targets, known as “anchors”, as well as nodes in the NLnog ring which can act as targets. There’s an Atlas anchor in Dublin, but that couldn’t take any more measurements, so that wasn’t suitable as a target, but HEAnet (the Irish R&E network) and Amazon (yep, the folks that sell books and whatnot) have NLnog ring nodes in Dublin.
We also needed targets in Northern Ireland that seemed to answer ICMP relatively unmolested, and I chose DNS servers at Tibus and Atlas/Bytel, both of whom are ISPs in the North. The final things to add were “controls”, so I chose a friend’s NLnog ring box which I know is hosted in London, and two other UK-based Atlas probes, the one I have on my network at home, and one on Paul Thornton’s network in Sussex. These effectively provided known UK-Ireland and UK-NI latencies to the targets, and a known NI-London latency for the probes in NI.
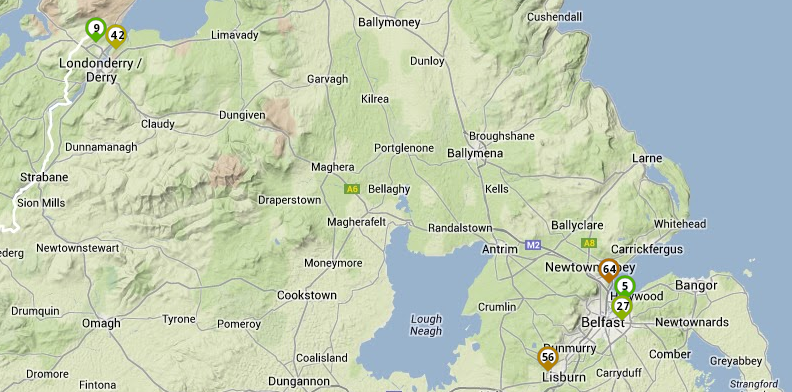
So, let’s look at round-trip time from Northern Ireland to the NLnog ring node in London:
ICMP RTT NI Probes to nuqe.net NLnog ring server
So, we can see there are some variations, no doubt based on last mile access technology. In particular, the node shown here with the 54ms RTT (just North of Belfast) consistently scored a high RTT to all test destinations. Anyway, this gives us an idea of NI-London RTT. The fastest being 15ms.
We can therefore make a reasonable assumption that if traffic were to go from Belfast to London and back to Ireland again, a 30ms RTT would be the best one could expect.
(For the interested, the two “control” test probes in the UK had latencies of 5ms and 8ms to the London target.)
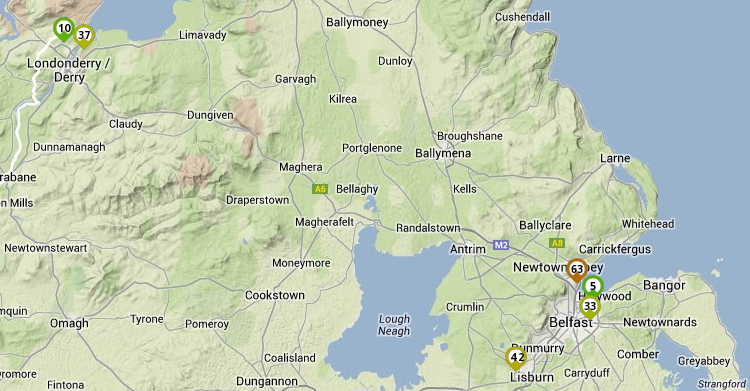
Now, take a look at the RTT from Northern Ireland to the node at HEAnet in Dublin:
ICMP RTT all NI probes to HEAnet NLnog ring node, Dublin
Only two of the probes in Northern Ireland have <10ms RTTs to the target in Dublin. All other probes have a greater RTT.
It is not unreasonable to assume, given that some have a >30ms RTT, or have exhibited a >15ms gain in RTT between the RTT to London and the RTT to Dublin, that this traffic is routing via London.
Of the two probes which show a <10ms RTT to HEAnet in Dublin, their upstream networks (AS43599 and AS31641) are directly connected to INEX.
Of the others, some of the host ASNs are connected to INEX, but the RTT suggests an indirect routing, possibly via the UK mainland.
The tests were also run against another target in Dublin, on the Amazon network, and show broadly similar results:
ICMP RTT all NI probes to Amazon NLnog ring node, Dublin
Again, the same two probes show <10ms RTT to Dublin. All others show >30ms. Doesn’t seem to matter if you’re a commercial or an academic network.
Finally, lets look at round trip times within Northern Ireland.
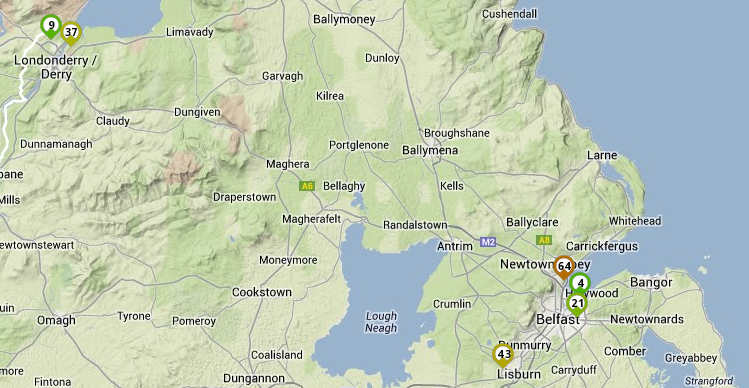
Here’s the test to a nameserver on the Tibus network:
ICMP RTT all NI Probes to Tibus Nameserver
Again, the same two probes report a lower than <10ms latency. I’d surmise that these are either routing via INEX, both host networks are downstream of the same transit provider in Belfast, or are privately interconnected in Belfast. At least two of the other nodes seem to route via the UK mainland.
To check this result, the same tests performed toward a nameserver on the Atlas/Bytel network:
ICMP RTT all NI probes to Atlas/Bytel Nameserver
Obviously, one of our probes is on-net, with a 1ms RTT!
Of the others, we’re definitely looking at “trombone routing” of the traffic, in most cases back to the UK mainland.
This may not be entirely surprising, as I’m told that BT don’t provide a 21CN interconnect node in Northern Ireland, so traffic on BT wholesale access products will “trombone” through the mainland in any case.
So, what’s really needed in Northern Ireland?
We’ve shown that if networks are willing to buy capacity to Dublin, they can happily exchange traffic at INEX and keep the latency down. An obvious concern some may have is the export of traffic from one jurisdiction to another, especially in light of recent revelations about systemic monitoring, if it’s NI to NI traffic.
The utility of IX in Northern Ireland could be hampered due to the lack of BT 21CN interconnect capability, as it may as well, for all intents and purposes be in Glasgow which is the nearest interconnect, for the traffic will still be making two trips across the Irish Sea whatever happens, assuming one end or the other is on the end of a BT wholesale pipe. (At worst, it could be 4 trips if both ends are on a BT pipe!)
If the goal is to foster internet growth (e.g. “production” of bandwidth) in Northern Ireland, where is it going to come from?
Are Northern Irish interests better served by connecting to the mature interconnect community in Dublin?
Is a BT 21CN interconnect in Belfast essential for growth, or can NI operators build around it?
Should INEX put a switch in Belfast? If they do, should it be backhauled to the larger community in Dublin? Or is that somehow overstepping the remit of an exchange point?
As some readers will know, I’m involved in running UKNOF – a series of regular meetings and a mailing list aimed at the UK Network Operations community. The next meeting is being held in London on 18th April, and we’re hoping it’s going to be one of the best attended UKNOF meetings we’ve had in a while.
The last few meetings in London have been so popular that we’ve outstripped the size of the venue that hosted the meeting, so this time we’ve gone for somewhere bigger still, which should allow us to go up to about 150-200 people. This is really important, as UKNOF is grounded in an ethos of openness, so having to turn people away really goes against the grain for us.
But accommodating every increasing numbers presents a challenge, because, best of all, there’s no charge to attend a UKNOF meeting. It’s paid for through the generosity of sponsors, and supported by individual volunteers from the community who put the meeting together.
For the upcoming UKNOF 25 meeting in April, we’ve already got a generous Platinum event sponsor in the shape of Ericsson, but so we’re able to maintain this momentum in the future, we’re working on building a supporting sponsor community.
There aren’t many conferences in our community which are run this way (free to attend) and open to all interested parties. They tend to be aimed at more specific communities (such as members of a particular IXP) or are invite only (such as the Network Field Day series). UKNOF is differentiated by it’s openness and transparent management.
The sponsorship of an open meeting such as UKNOF benefits the Network Ops industry in the UK by lowering the bar to attend, which has the effect that we get a broad audience from the community.
So, if a sponsor is ever thinking about helping UKNOF, think about how it fits in with your Corporate Social Responsibility goals.
We get people at UKNOF that simply wouldn’t have the budget (or get managerial permission) to attend the typical industry conference, which would have a registration fee in the hundreds of pounds, may need expensive overnight stays in flashy hotels, you get the gist. If a company is going to spend that sort of money on sending someone to an event, they are going to send their top bods, and not necessarily the guy at the coal face.
Yet the target of UKNOF isn’t just the experienced engineer who already knows it, it’s those who haven’t been around as long, those who are in a position to learn from those who’ve been around the block a couple of times – UKNOF’s main raison d’etre is often said to be “distribution of clue” – knowledge sharing and information exchange.
So we’re really glad that we don’t just get the “usual suspects” from the global Internet meeting circuit at UKNOF, but a real cross-section of the UK Net Ops community – we can use UKNOF to bring the best of the content (and well known speakers) from the global circuit to a UK audience that can’t get to the bigger meetings, and cover topics which are closer to home and of specific interest to the local community.
I’m currently at the APRICOT 2013 conference in Singapore. The conference has over 700 registered attendees, and being Internet geeks (and mostly South-East Asian ones, at that), there are lots of wifi enabled devices here. To cope with the demands, the conference does not use the hotel’s own internet access.
Anyone who’s been involved with Geek industry events knows by painful experience that most venue-provided internet access solutions are totally inadequate. They can’t cope with the density of wifi clients, nor can their gateways/proxy servers/NATs cope with the amount of network state created by the network access demands created by us techies. The network disintegrates into a smouldering heap.
Therefore, the conference installs it’s own network. It brings it’s own internet access bandwidth into the hotel. Usually at least 100Mb/sec, and generally speaking, a lot more, sometimes multiple 1Gbps connections. The conference blankets the ballrooms and various meeting rooms in a super high density of access points. All this takes a lot of time and money.
According to the NOC established for the Conference, most concurrent connections to the network are over 1100, s0 about 1.6 devices per attendee. Sounds about right: everyone seems to have a combination of laptop and phone, or tablet and phone, or laptop and tablet.
One thing which impressed me was how the hotel hosting the conference has worked in harmony with the conference. Previous experience has been that some hotels and venues won’t allow installation of third party networks, and insist the event uses their own in house networks. Or even when the event brings it’s own infrastructure, the deployment isn’t the smoothest.
Sure, we’re in a nice (and not cheap!) hotel, the Shangri-La. It’s very obviously got a recently upgraded in-house wifi system, with a/b/g/n capability, using Ruckus Wireless gear. The wifi in the rooms just works. No constant re-authentication needed from day-to-day. I can wander around the hotel on a VOIP call on my iPhone, and call quality is rock solid. Handoff between the wifi base stations wasn’t noticeable. Even made VOIP calls outside by the pool. Sure, it’s a top-notch five-star hotel, but so many supposedly equivalent hotels don’t offer such a stable and speedy wifi, which makes the Shangri-La stand out in my experience.
There’s even been some anecdotal evidence that performance was better over the hotel network to certain sites, which is almost unheard of!
(This may be something to do with the APRICOT wifi being limited to allow only 24Mb connections on their 802.11-a infrastructure. Not sure why they did that?)
As the Shangri-La places aesthetics very high on the list of priorities, they weren’t at all in favour of the conference’s NOC team running cables all over the place, so their techs were happy to provide them with VLANs on the hotel’s switched infrastructure, as well as access to the structured cabling plant.
This also allowed the APRICOT NOC team to extend the conference LAN onto the hotel’s own wifi system – the conference network ID was visible in the lobby, bar and other communal areas in the hotel without having to install extra (and unsightly) access points into the public areas.
This is one of the few times I’ve seen this done and seen it actually work.
So, in the back of my mind, I’m wondering if we’re actually turning a corner, to reach a point where in-house wifi can be depended on by event managers (and hotel guests!) to such an extent they don’t need to DIY anymore?

 Audio isn’t a problem. A rather nice Allen & Heath desk is permanently installed, and the standard rig includes plenty of radio handheld and lapel mics, and sidetone/foldback is provided for the presenter. On the day desk will be looked after by a professional sound engineer.
Audio isn’t a problem. A rather nice Allen & Heath desk is permanently installed, and the standard rig includes plenty of radio handheld and lapel mics, and sidetone/foldback is provided for the presenter. On the day desk will be looked after by a professional sound engineer.